
K8s如何调度Pod
Pod的调度主要分为两个阶段,主要是调度周期和绑定周期,调度周期决定Pod被调度到哪一个节点,绑定周期将决策运用到集群。调度周期和绑定周期成为“调度上下文”。
调度周期
- 发现未被调度的Pod:调度器通过K8s的watch机制来发现集群中新创建且尚未被调度到节点的Pod。kube-scheduler位于集群控制面,是k8s的默认调度器,主要负责将一个pod调度到一个节点上。
- 选择节点:在选择节点时包含过滤和打分两个步骤来选择合适的节点进行调度。
- 在过滤阶段,调度器会选择一系列符合pod调度需求的节点
- 在打分阶段,调度器会对可调度节点队列中的每一个节点进行打分
- 最终pod会被调度到分数最高的节点上面
调度框架-调度器插件
调度框架是k8s调度框架的一种插件架构,提供了一系列API插件来实现大部分的调度功能,这些调度插件被注册后在一个或多个拓展点被调用。
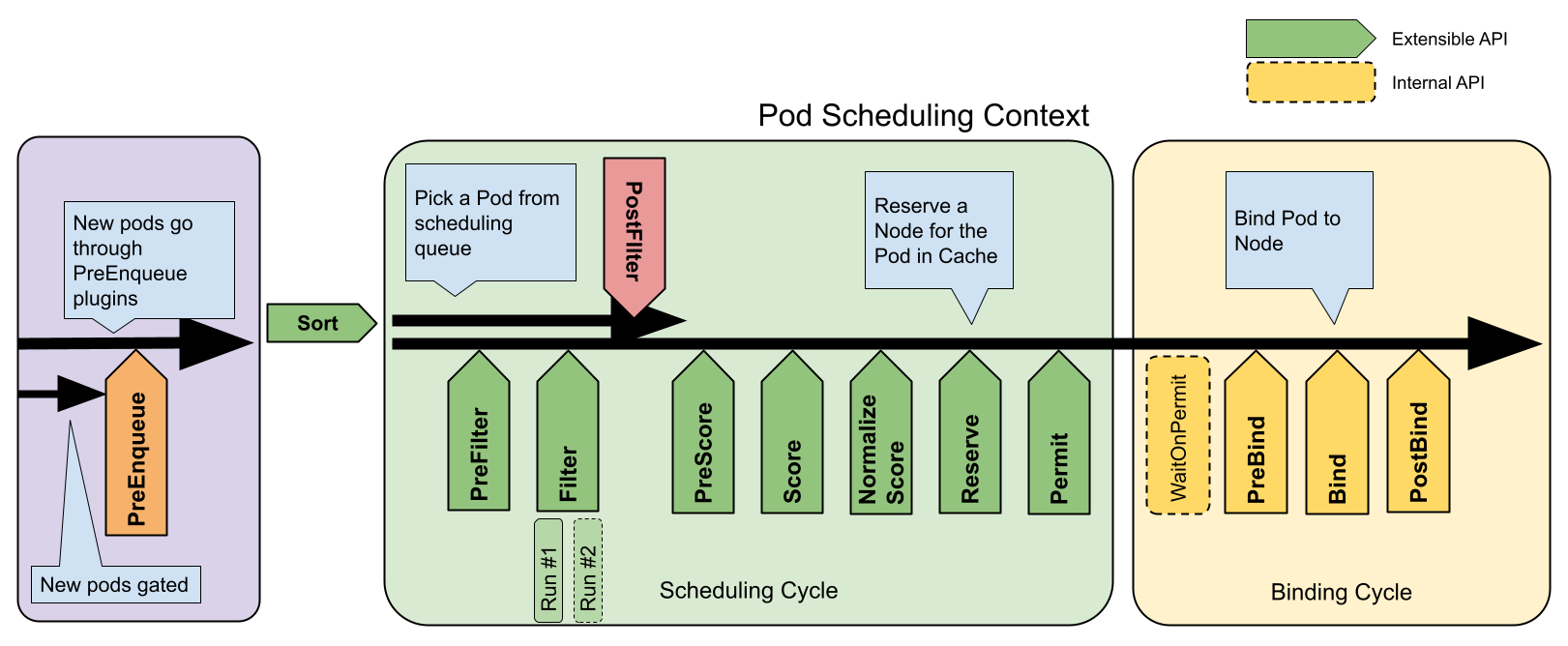
内置调度器插件可以启用或禁用,大部分默认调度器都默认启用。如果要启用调度器,可以修改配置文件:
1 | apiVersion: kubescheduler.config.k8s.io/v1alpha1 |
默认配置文件地址为在/etc/kubernetes/scheduler.conf。
除了默认的插件,可以实现自己的插件,并和默认插件一起配置。你可以访问 scheduler-plugins 了解更多信息。
源码分析
Scheduler结构体
1 | // Scheduler监听新的Pod,试图找到适合的节点并且绑定写回api server |
Scheduler启动主循环
Scheduler结构体定义了一个方法Run,它用来启动结构体的主循环,即启动调度器:
1 | // 开始监听和调度Unschedule状态的Pod,阻塞式的,直到上下文关闭 |
wait.UntilWithContext函数在指定的上下文中循环执行给定的函数,ctx为传入的context,用来当ctx.Cancle或ctx.Done之后,会执行第10行的代码,即关闭SchedulingQueue。sched.scheduleOne为循环执行的函数,0即为执行一次。
我们来看下Scheduler.scheduleOne函数:
1 | // scheduleOne 对单个 pod 进行完整的调度工作流程,它在调度算法的主机拟合(host fitting)上进行串行化处理 |
host fitting,即主机拟合,是指将一个容器化的应用程序(通常是一个 Pod)调度到集群中的一个合适的节点(即主机)上运行的过程。
这个函数比较长,执行过程主要是:
- 1.阻塞式获取下一个Pod,当schedulerQueue被关闭时退出
- 2.sched.frameworkForPod方法用来获取Pod中指定的调度器
Pod.Spec.SchedulerName用来指定Pod使用的调度器名称,默认是default。Kubernetes可以支持从头开始编写Scheduler,如果是自己实现的Scheduler,就可以在这个字段为Pod指定调度器。 - 3.调度是否能被跳过:
- 如果Pod正在被删除即跳过
- 如果某个 Pod 在调度队列中被取出进行调度尝试之前,收到了更新事件(如 Pod 的 Spec 发生了变化),那么该 Pod 将会被标记为假设状态,并不会进行实际的调度尝试,以避免重复调度。
- 4.概率性开启调度器插件统计指标的flag标志位
- 插件指标是指在 Kubernetes Scheduler 中使用的调度插件(例如调度算法、优先级函数等)生成的性能指标或统计信息。这些指标通常用于监控和度量调度器的性能、效果和健康状态,以便在需要时进行调优和故障排除。
- 在调度循环中,调度器可能会调用多个调度插件来评估节点的可用性、计算权重、比较优先级等。这些插件可能会在执行时生成各种指标,例如调度时间、节点利用率、调度决策等。记录这些插件指标可以帮助管理员和开发人员深入了解调度器的行为和性能,并进行优化和故障排除。
- rand.Intn是 Go 语言标准库 math/rand 包中的一个函数,用于生成一个指定范围内的随机整数
- 5.尝试调度单个Pod,如果调度失败,则调用FailureHandler函数进行处理
- 6.调度成功,开启一个新的Goroutine
- 使用Prometheus记录监控指标,metrics.SchedulerGoroutines 和 metrics。Goroutines,用于度量调度器的 Goroutine 数量
- 调用sched.bindingCycle将Pod绑定到节点上,绑定失败,则使用sched.handleBindingCycleError处理错误
Scheduler调度
我们看到上述代码中sched.schedulingCycle用来调度Pod,我们看看代码:
1 | // schedulingCycle尝试调度单个Pod |
依然这段代码比较长,但是总体内容比较简单:
- 1.使用sched.SchedulePod对Pod进行模拟调度,返回一个scheduleResult,记录了调度结果Node的信息。
接下来是一系列错误判断:- 没有可用的节点
- 断言为FitError类型的错误,即选择节点时出现了不符合条件的错误,没有可用节点
- 如果没有可用节点,且设置了PostFilterPlugins调度器插件,将实行抢占策略
- 运行RunPostFilter插件尝试使pod在未来可以被调度
- 2.记录metric指标,计算从开始时间 start 到当前时间的运行时延,并将其观测(Observe)到 metrics.SchedulingAlgorithmLatency 指标中
- 3.调用
sched.assume告诉缓存假定 pod 现在正在给定节点上运行,即使它尚未绑定。这使我们可以继续进行调度,而无需等待绑定发生。 - 4.使用reserve插件的RunReservePluginsReserve方法,在pod实际绑定到节点之前,为Pod预留资源、标记节点或其他预留操作
预留失败则调用RunReservePluginsUnreserve清理预留状态,然后用sched.Cache.ForgetPod(assumedPod) 方法将 assumedPod 从调度器的缓存中删除,以便后续的调度可以重新考虑这个Pod - 5.接下来,调用了调度器中的许可插件的 RunPermitPlugins 方法。许可插件是调度器的一部分,用于检查是否允许将 Pod 绑定到某个节点
- 6.如果存在待激活的Pod,将其放入调度队列中,进行进一步的调度处理,并清空待激活的Pod列表
- 最后返回调度结果,Pod信息
“待激活”(Pending Activation)是指已经被调度器选择为将要在某个节点上运行的 Pod,但由于某些原因还没有被激活,即还没有被添加到调度队列中进行实际的调度处理。通常情况下,Pod 需要在被激活后才能被真正调度到节点上运行。
Scheduler绑定到节点
1 | // bindingCycle tries to bind an assumed Pod. |
- 1.首先通过调用 fwk.WaitOnPermit(ctx, assumedPod) 方法等待 “permit” 插件的完成状态。
- “permit” 插件通常用于在实际进行 Pod 调度之前进行进一步的验证和确认,例如检查节点资源是否满足要求、检查节点的亲和性和反亲和性等条件是否满足等。这些插件可以对 Pod 进行更细粒度的筛选和过滤,以确保 Pod 能够在合适的节点上运行。
- 2.执行 “prebind” 插件的逻辑,通过调用 fwk.RunPreBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost) 方法运行 “prebind” 插件。
- “prebind” 插件通常用于在进行 Pod 节点绑定(binding)之前进行一些预处理操作,例如修改 Pod 的标签、注解、亲和性和反亲和性等信息,以及进行其他一些验证和准备工作。这些插件可以在节点绑定之前对 Pod 进行进一步的处理和调整,以确保 Pod 在节点上的调度和运行是合理和符合预期的。
- 3.调用 sched.bind(ctx, fwk, assumedPod, scheduleResult.SuggestedHost, state) 方法运行 “bind” 插件。
- 根据拓展器插件 > 框架插件的优先级,调用extender.Bind方法,将Pod绑定到节点
- “bind” 插件用于在进行 Pod 节点绑定(binding)时进行实际的节点绑定操作,将 Pod 绑定到指定的节点上,使其在该节点上运行。这些插件通常会处理节点资源的分配、Pod 节点状态的更新、调度事件的记录和报告等操作,以确保节点绑定的正确执行和状态的一致性。
- 4.执行 “postbind” 插件的逻辑,通过调用 fwk.RunPostBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost) 方法运行 “postbind” 插件。
- “postbind” 插件用于在进行 Pod 节点绑定(binding)后进行一些后续的操作,例如更新节点状态、记录事件、发送通知等。这些插件通常会处理节点状态的更新、调度事件的记录和报告、通知相关组件等操作,以确保节点绑定后的一致性和完整性
Scheduler总结
